浪潮实习——两种预计算推荐算法的总结
面向时序数据库的预计算推荐系统
摘要
随着数据量的激增,时序数据库在面对复杂查询分析时,往往效率不高。为了解决该问题,预计算发挥着重要作用,因为它可以将复杂查询的结果持久化存储,为后续查询省去了重新计算的时间。然而,当前所有时序数据库都需要用户手动去创建预计算,需要对具体场景有较为深入的理解,对普通用户极为不友好。因此本文设计了面向时序数据库的预计算推荐系统,自动分析数据库中的负载信息,并根据基于规则和基于收益两种算法自动为用户推荐合适的预计算,以提升数据库的查询性能,减少用户的响应时间。实验表明该方案相比于传统的预计算推荐方案能够带来更高的查询效率的提升。
1、引言
时间序列数据是指按照时间顺序记录的数据点,它们在许多领域中都非常常见,例如金融交易记录、气象监测数据、工业设备传感器数据等。时序数据普遍具有产生频率高、数据规模大的特点,例如,三一重工在生产的每台重型机械上安装了多种类型的传感器以搜集各种参数,如机械的开关信号、GPS信息、发动机参数等,用以监控重型机械的运转情况[1]。时序数据库(Time Series Database, TSDB)是专为处理此类时间序列数据而设计的数据库系统,它们在时序数据的存储、查询和分析方面具有独特的优势,这些数据库在工业物联网、数字能源、金融等多个领域都已成功完成落地实践,特别适用于处理大规模的时序数据。
然而近年来,随着信息技术的快速发展,各个领域的数据量正以前所未有的速度增长,比如在工业物联网中,各种设备和传感器产生的时序数据正在爆炸式地增长,给数据查询和分析带来了巨大的挑战。当用户在进行大规模的复杂查询分析时,处理速度往往显著下降,进而极大的影响了用户的体验。因此,优化数据库的查询性能,提高数据处理效率,已成为当前时序数据库技术发展的关键方向。
为了解决上述问题,时序数据库针对复杂查询分析进行了优化,主要分为三种方法,分别是分布式架构、索引优化和预计算。(1)分布式架构:分布式时序数据库通过分布式计算和存储,提高了处理大规模数据集的能力,优化了复杂查询的性能;(2)索引优化:通过采用特定的索引结构,如时间索引、标签索引等,以提高查询效率。(3)预计算:预计算技术可以将复杂查询的结果持久化存储,从而在查询时直接使用,当查询可以匹配相应的预计算时,可以直接利用已有的结果,省去了重新计算的时间。
分布式架构和索引优化相比于预计算,存在几个潜在的缺点,在查询执行时仍然无可避免地需要对已有数据进行大量计算,这可能导致查询响应时间较长,尤其是在数据量巨大的情况下。相比之下,预计算技术具有很多好处:(1)快速响应时间:预计算通过预先计算和存储查询结果,能够显著减少查询响应时间。当查询被执行时,可以直接从预计算的结果中获取数据,而不是实时计算,这在数据量非常大时尤其有价值。(2)支持高并发:预计算结果可以被多个用户共享,这意味着系统可以同时处理更多的查询请求,提高了并发处理能力。(3)灵活性和扩展性:预计算技术可以与现有的分布式架构和索引优化技术一起使用,提供更灵活的数据处理和查询能力。然而当前所有时序数据库都需要用户手动去创建预计算,需要用户对具体场景有较为深入的理解,对于普通用户极为不友好。
本文旨在设计一种面向时序数据库的预计算推荐系统,自动收集并分析数据库中的负载信息,并提出基于规则和基于收益两种预计算推荐算法为用户推荐合适的预计算:基于规则的算法采用贪心策略进行推荐;基于收益的算法采用深度学习的方法精确估计预计算的收益进行推荐,推荐的预计算可以提升数据库的查询性能,减少用户的响应时间。本文的主要贡献如下:
我们设计了一种面向时序数据库的预计算推荐系统。
我们设计了一种基于规则的预计算推荐算法,采用贪心的思想,使得推荐的一个预计算尽可能匹配更多的查询。
我们设计了一种基于收益的预计算推荐算法,采用深度学习的方法对预计算的收益进行估计,并建模为整数规划问题,使得推荐的预计算在存储空间受限的场景下最大化查询效率,从而解决基于规则的预计算推荐算法在存储空间受限的场景下不适用的问题。
我们进行了大量实验验证了本文的预计算推荐算法相比于传统预计算推荐算法在提高查询性能方面的优越性。
本文的其余部分组织如下。在第二节中,我们介绍了相关的工作。在第三节中,我们对相关问题进行了定义。在第四节中,我们提出了我们的预计算推荐算法。在第五节给出了实验结果。我们得出的结论在第六节。
2、相关工作
当前所有时序数据库都针对复杂查询分析进行了优化,主要分为三种方法,分别是分布式架构、索引优化和预计算。
(1)分布式架构:TimescaleDB[6]扩展了PostgreSQL,通过超级表(Hypertables)实现分区和分片。每个Hypertable可以分成多个块(Chunk),这些Chunk可以分布在不同的节点上。当进行查询时,利用PostgreSQL的并行查询能力,TimescaleDB可以在多个节点上并行执行查询操作,从而提高查询性能。TDengine[7]将数据按照时间范围进行分片,每个分片存储在不同的数据节点上。通过这种方式,查询操作可以并行地在多个分片上执行,从而提高查询速度。分片机制能够有效减少单个节点的负载,避免查询瓶颈。
(2)索引优化:InfluxDB[5]主要通过时间戳索引来加速时间范围查询。时间戳是所有数据点的关键属性,查询通常基于时间范围进行。除了时间戳索引,还使用了标签来标识数据点的属性,标签索引可以加速基于标签的过滤查询。标签是键值对形式,可以用于高效查询和聚合。TDengine同样使用了多级索引结构,包括时间索引和标签索引,以加速时间范围查询和标签过滤查询。
(3)预计算:OpenTSDB[4]中实现了Rollup和Pre-aggregates,Rollup是一种数据汇总技术,它可以将原始的高分辨率数据按照一定的规则进行聚合,生成低分辨率的数据。这样做的好处是可以减少存储需求,提高查询性能,并且可以更好地处理大规模的时间序列数据。Rollup可以按照时间间隔(例如每小时、每天、每周等)来进行数据聚合,也可以按照指定的标签(例如按照不同的设备、地区等)来进行聚合。Pre-Aggregates是一种预先计算并存储好的聚合数据,在OpenTSDB中,用户可以通过定义预先计算的聚合函数(例如求和、平均值、最大值、最小值等)和时间间隔来创建Pre-Aggregates。一旦创建了Pre-Aggregates,系统就会在后台定期计算并存储好这些聚合数据,用户可以在查询时直接使用这些预先计算好的聚合数据,而不需要实时计算。这样可以大大提高查询性能,并且可以降低对底层存储的压力。InfluxDB支持CQ(continous query)的功能,CQ通过定期 pull 原始时序数据进行计算,将计算结果存储在内部特殊metric 中。用户通过创建 CQ 来实现对数据预处理。TDengine中实现了SMA索引,即Small Materialized Aggregates,提供基于数据块的自定义预计算功能。如果查询处理涉及整个数据块的全部数据,直接使用预计算结果,完全不需要读取数据块的内容。由于预计算数据量远小于磁盘上存储的数据块数据的大小,对于磁盘 I/O 为瓶颈的查询处理,使用预计算结果可以极大地减小读取 I/O 压力,加速查询处理的流程。
然而,分布式架构和索引优化在查询执行时仍然无可避免地需要对已有数据进行大量计算,导致查询响应时间较长。相比之下,预计算技术具有很多好处,通过预先计算和存储查询结果避免了大量计算。但是,预计算都需要用户手动生成,需要用户对具体场景有较为深入的理解,对于普通用户极为不友好。因此我们设计了一种面向时序数据库的预计算推荐系统,自动分析数据库中的负载信息,并根据基于规则和基于收益两种算法自动为用户推荐合适的预计算,以提升数据库的查询性能,减少用户的响应时间。
3、问题定义
3.1查询和预计算
时序数据库中的查询带有特有的时间信息,查询语句主要由以下几点构成:时间间隔,聚合函数,时间范围。以如下KaiwuDB中的一条普通查询为例子:
1 | |
该查询是指在cpu这张表上,在时间范围为[2023-01-01 00:00:00,2023-01-06 00:00:00]内,每隔时间间隔60s,生成usage_user列上的max聚合结果。
预计算语句类似于查询语句,不同的地方在于预计算语句无需指定时间范围,它会自动在表上进行预计算任务。
1 | |
该预计算语句是指在cpu这张表上进行预计算任务,即每隔时间间隔60s对usage_user列进行max聚合计算。
3.2预计算匹配
第 i 条查询 q_i 可以匹配到第 j 条预计算 p_j 的条件是:q_i 的聚合函数集合 g_i 是 p_j 聚合函数集合 g_j 的子集,并且 q_i 的时间间隔 I_i 要为 p_j 时间间隔 I_j 的整数倍,即:
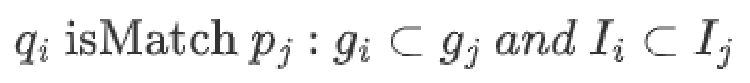
3.3预计算收益和成本
第 j 条预计算 p_j 能够为第 i 条查询 q_i 带来的收益为 B_i,j,即 q_i 的原始查询时间 t_i 减去该查询匹配预计算 p_j 的查询时间 t_i,j。 p_j 的成本 c_j 为其本身所占有的存储空间。
3.4整数规划问题求解器
Gurobi是由美国Gurobi Optimization公司开发新一代大规模优化器。无论在生产制造领域,还是在金融、保险、交通、服务等其他各种领域,当实际问题越来越复杂,问题规模越来越庞大的时候,需要一个经过证明可以信赖的大规模优化工具,为决策提供质量保证。在理论和实践中,Gurobi优化工具都被证明是全球性能领先的大规模优化器,具有突出的性价比,可以为客户在开发和实施中极大降低成本。
应用最广泛的数学规划问题类型包括:混合整数线性规划(MILP)、混合整数二次凸规划(MIQP/MIQCQP)、混合整数非线性规划等。Gurobi 是唯一一个可以适用上述全部类型,并且在每一个类型中都排名第一,并且大幅度领先第二名的优化器。第三方评比报告做出了明确说明[1]。
4、预计算推荐系统的整体架构
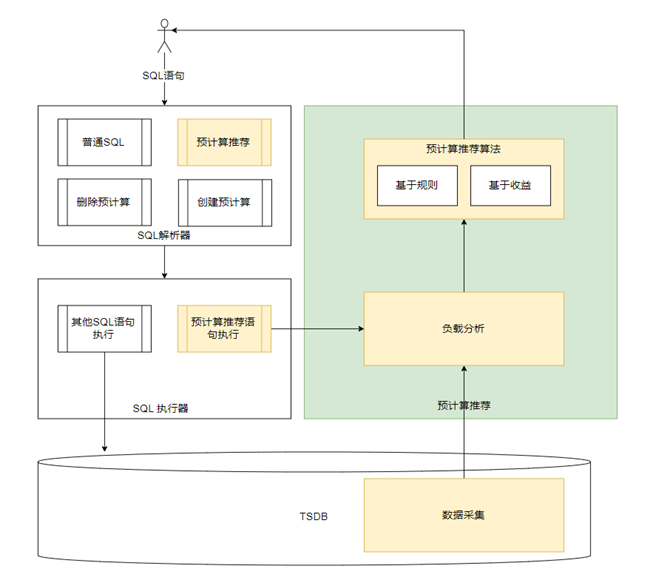
在本节中,我们介绍了面向时序数据库的预计算推荐系统的整体架构,主要分为三个部分,如图1所示,包括数据采集、负载分析和预计算推荐三个部分。在数据采集和负载分析中,我们采集相应的数据并对数据进行分析,从而理解数据库的使用模式和用户行为,为预计算推荐算法做支撑。在预计算推荐中,我们首先实现了一种基于规则的预计算推荐算法,该算法采用贪心的思想为用户推荐出相应的预计算以提升数据库的运行效率。接着,为了克服基于规则的预计算推荐算法在存储空间受限的场景下不适用的缺点,我们又提出了基于收益的预计算推荐算法,采用深度学习的方法对预计算收益进行估计,实现了更好的推荐效果。
4.1数据采集
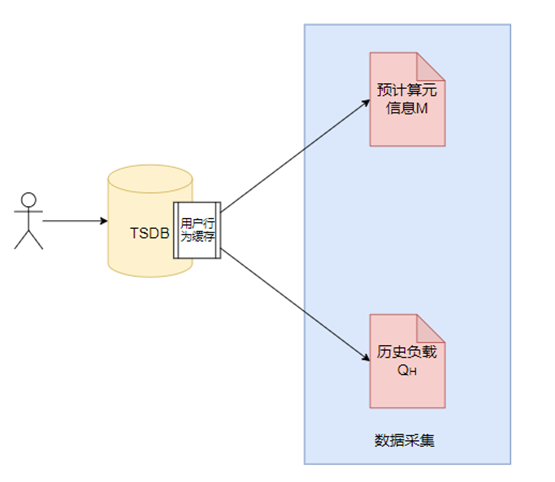
数据采集是预计算推荐系统中的入口,负责采集数据库中的历史负载信息 和预计算元信息 ,如图2所示。这些信息的收集对于深入理解数据库的使用模式、用户行为以及优化查询性能至关重要。
采集的信息可以分为两类:(1)历史负载信息 :历史负载信息主要是用户的查询SQL记录,通过对历史负载信息的分析,系统能够识别出常见的查询模式和用户偏好,这对于设计好的预计算推荐算法而言至关重要。(2)预计算元信息 :预计算元信息提供了对预计算使用情况的全面视图,包括预计算的使用次数、最近使用时间、资源消耗情况等基本信息。使用次数能够反映预计算的活跃度和用户依赖程度;最近使用时间则有助于识别那些可能已经过时或不再符合当前查询需求的预计算;资源消耗情况,如CPU时间、内存使用量和I/O操作,能够揭示预计算对系统资源的实际影响,为资源管理和性能调优提供依据。
数据采集的深度和广度直接影响着预计算推荐系统的性能和效果。通过持续的数据采集和分析,系统能够不断进化,更好地服务于用户。
4.2负载分析
负载分析是预计算推荐系统中的核心环节,它通过对采集的数据进行深入分析,挖掘用户使用数据库的规律性,为预计算推荐算法提供关键支持,如图3所示。
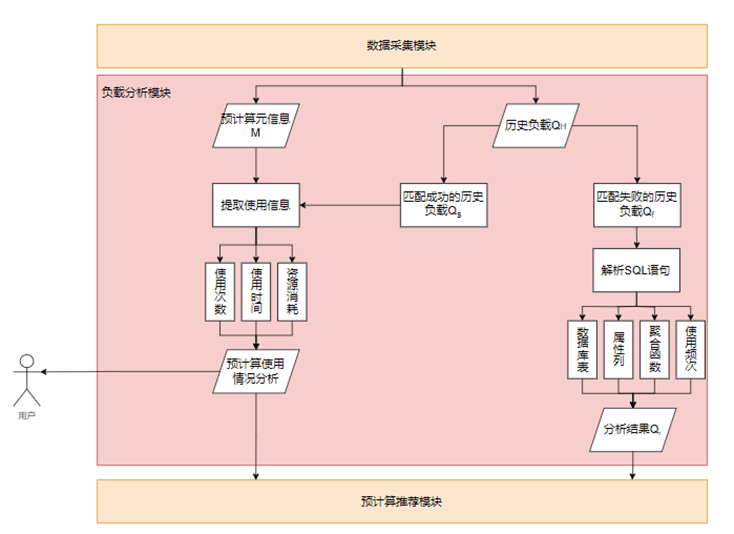
负载分析主要包含两大类,对匹配成功的历史负载 和已有预计算元信息的分析和对匹配失败的历史负载 的分析:(1)对匹配成功的历史负载和已有预计算元信息的分析:对于成功匹配的负载,分析的重点在于评估预计算的使用效果,包括其对查询性能的提升程度和资源消耗情况。通过这种分析,可以识别出哪些预计算是高效的,哪些可能需要进一步的调整或优化。此外,对成功匹配的负载进行分析,还可以帮助用户更好地理解预计算的实际效益,从而做出更加合理的使用决策,这些分析的结果用于支持未来的预计算监控设计。(2)对匹配失败的历史负载的分析:对于匹配失败的预计算的历史负载,负载分析则更加注重于识别和理解查询模式,包括涉及的数据库、表、列、聚合函数、时间窗口和查询频次等关键信息,这些信息被转化为相应的数据结构,为预计算推荐算法提供了丰富的输入。预计算推荐算法可以推荐新的预计算来覆盖这些未被匹配的查询,实现查询效率的提升。
总而言之,负载分析是预计算推荐系统中不可或缺的一环,通过对采集数据的全面分析,负载分析不仅为预计算推荐算法提供了坚实的数据基础,还为用户提供了宝贵的洞察,帮助他们更好地理解和利用预计算,从而实现数据库查询性能的持续优化和提升。
4.3预计算推荐
在本节中,我们首先实现了一种基于规则的预计算推荐算法,可以为用户推荐出相应的预计算以提升数据库的运行效率。接着,为了克服基于规则的预计算推荐算法在存储空间受限的场景下不适用的缺点,我们又提出了基于收益的预计算推荐算法,实现更好的推荐效果。
4.3.1基于规则的预计算推荐算法
基于规则的推荐算法采用贪心的思想,即一个预计算表尽可能支持匹配更多的查询,预计算与用户查询的关系为1:n的关系,即一个预计算可以服务多个不同的查询,所以推荐的预计算结果的聚合函数集合应该尽可能包含更多查询的聚合函数。推荐结果中的时间间隔尽可能采用匹配此预计算的历史负载中更小的时间间隔。具体算法如下:
假设待推荐预计算的目标表为 T,我们对Q_r以时间间隔interval为分组的查询语句表示为集合Q={q_1,q_2…q_n}。设基于规则的推荐算法为F,推荐结果为PC,那么该推荐任务可以形式化表述为PC=F(T,Q),具体的:提取所有查询Q中的interval,表示为I={i_1,i_2…i_n},提取所有查询Q中的聚合函数,表示为G={g1,g2…gn} 。推荐算法F表示为:首先从历史查询中找出最小的interval,作为候选interval,即I_c=min(I)。然后查找I中所有I_c的整倍数的interval,表示该PC_c可以同时服务于这些interval的查询,记为候选查询 Q_c。从聚合函数中提取候选查询Q_c包含的聚合函数G_c,通过DDL构建模块构造预计算创建语句: 并加入PC中。然后继续从Q中剔除已经推荐过预计算的查询Q_c,为剩余的查询重新贪心规则继续推荐预计算,直到Q为空。最终为用户推荐出的预计算集合为PC,用户可以根据需要选择实现。

4.3.2基于收益的预计算推荐算法
由于基于规则的预计算推荐算法采用贪心的思想,推荐的预计算结果不考虑成本,在存储空间受限的场景下就不再适用。因此我们提出了一种基于收益的预计算推荐算法,采用深度学习的方法对预计算的收益进行估计,并建模为整数规划问题,可以在存储空间受限的场景下推荐收益最高的预计算。我们的算法包括以下步骤:预计算候选的生成、预计算估计、预计算选择,下面我将详细说明。
A.预计算候选的生成
假设待推荐预计算的目标表为T,在预计算候选生成阶段,我们对工作负载按照时间间隔进行分组为Q={q_1,q_2…q_n},提取所有时间间隔interval表示为 I={i_1,i_2…i_n};提取聚合函数表示为G={g1,g2…gn},针对每组 g_i 统计聚合函数的出现频率,并根据3sigma原则淘汰掉出现频率过低的聚合函数,剩余的聚合函数作为每组的聚合函数代表G’ ,最终会为每个分组构造一条预计算候选P=DDL{T,I,G}。
B.预计算估计
预计算估计包含两个部分,分别是对成本的估计和对收益的估计。
(1)成本估计
- 成本估计公式如下:
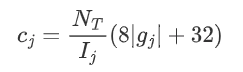

(2)收益估计
收益的估计采用深度学习方法进行,输入为一条查询语句 q_i 和一条预计算语句 p_j ,输出为这条预计算为该查询带来的收益B_i,j 。
首先需要对查询和预计算的SQL语句进行特征提取,我们提取的特征包括聚合函数、查询中子表(设备)的个数、时间范围信息、时间间隔信息。以如下SQL为例子:
1 | |
进行特征提取后:
1 | |
然后,我们需要对查询和预计算的聚合函数进行排序,防止因聚合函数输入次序不同带来的对输出结果的影响。接下来我们对特征进行编码,字符特征采用One-Hot编码,数值特征进行归一化。最后将编码后的向量进行Concat送入多层神经网络中,输出为收益的估计,模型整体框架如下图所示,
收益估计模型如下:
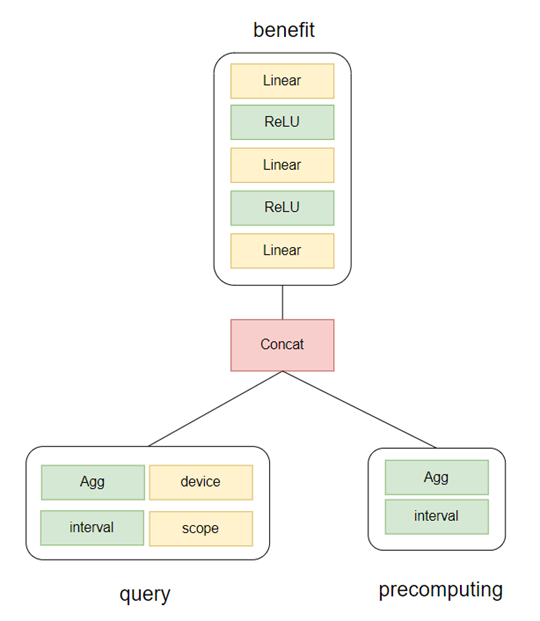
C.预计算选择
预计算选择问题是指从预计算候选中选择最终的预计算集合,以最大化查询效率。我们可以将问题建模为整数线性规划问题,即在存储空间受限的前提下,选择能够最大化收益的预计算集合,形式上,我们将该问题定义如下:
建模为整数线性规划问题:

算法如下:

5、预计算推荐算法实验与结果分析
5.1实验设置
5.1.1实验环境
本文的实验由Python语言进行编写,操作系统以及一些用到的软件的版本分别如下:
操作系统:Windows 10
Python版本:Python 3.7.5
IDE: Pycharm 2020.2
数据库:KaiwuDB 1.2
KaiwuDB是一款由浪潮公司开发的分布式多模数据库,它特别适用于处理大规模的时序数据。当前,KaiwuDB 在工业物联网、数字能源、金融等均已成功完成落地实践[11],它特别针对时序数据进行了优化,使其在时序数据库领域中具有竞争力,特别是在需要处理大规模时序数据和实时分析的业务场景中。
实验中用的机器的主要配置为:CPU Intel® Core™ i7-9750H,内存 16GB 2666 MHz,硬盘1TB。
5.1.2数据准备
A.数据集
使用TSBS测试工具生成数据集[10]。目前 TSBS 支持 IOT 及 Devops 两种场景:
我们设置日期在[2016-01-01 08:00:00, 2016-01-31 08:00:00]范围内,设备数量为100。
B.查询
使用TSBS测试工具生成查询工作负载,目前TSBS在CPU-ONLY场景下支持15种查询工作负载[10]。我们选择其中符合预计算推荐规则的查询语句进行生成。
5.1.3 Baseline
A.收益模型对比算法:
线性回归模型(LR):一种使用线性函数来建模收益的机器学习方法,并使用欧几里得距离计算估计收益与实际收益之间的损失。
梯度提升模型(GBDT):一种基于XGBoost的梯度提升决策树回归方法。
深度神经网络(DNN):一种具有多个隐藏层的人工神经网络。
指标:MAPE(Mean Absolute Percent Error):对于预测收益值 和真实值 , 。
B.预计算推荐对比算法:
TopkFreq:选择历史负载中出现频率最高的语句作为预计算进行推荐。
TopkOver:选择历史负载中代价最小的语句作为预计算进行推荐。
TopkBen:选择历史负载中收益最高的语句作为预计算进行推荐。
Rule-Based:基于规则的预计算推荐算法。
Benefit-Based:基于收益的预计算推荐算法。
指标:收益模型估计的收益。
5.2实验结果
5.2.1基于规则的预计算推荐算法效果实验
在本节中,我们生成了90条查询用于评估基于规则的预计算推荐算法的效果,执行流程:打开预计算推荐开关,执行—遍所有查询,执行预计算推荐命令,根据推荐创建预计算,再执行—遍所有查询,观察两次查询的时间。
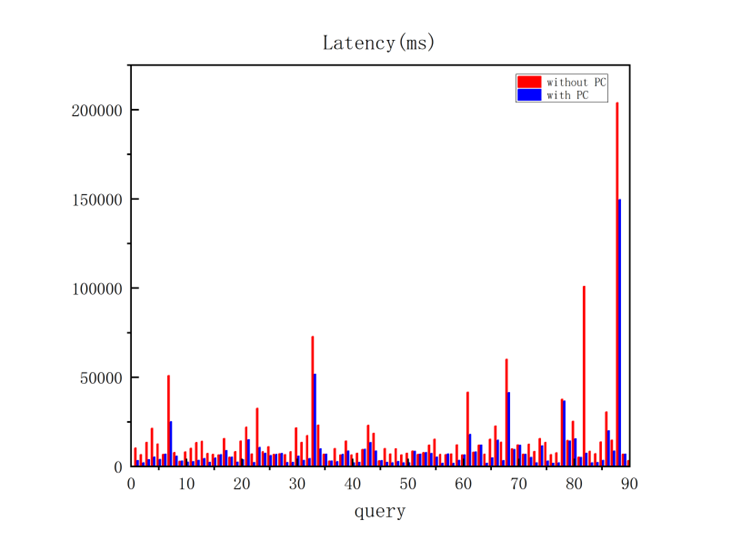
如图所示,红色是不使用预计算的查询时间,蓝色是使用预计算的查询时间。根据实验结果可以看到,使用预计算的查询时间明显减少,推荐结果有效。
5.2.2收益模型估计实验
我们比较LR、GBDT和DNN的MAPE
| MAPE | Median | 90th | 95th | 99th | Max | Mean |
|---|---|---|---|---|---|---|
| LR | 15.54 | 40.67 | 42.36 | 151 | 361 | 37.32 |
| GBDT | 0.726 | 2.80 | 5.33 | 31.7 | 101 | 1.96 |
| DNN | 0.575 | 2.61 | 4.93 | 27.0 | 137 | 1.78 |
5.2.3预计算推荐算法的对比实验
在本节中,我们生成一批历史负载,将我们的预计算推荐算法与现有的预计算推荐算法进行比较,并基于收益模型评估它们的效果。

如图所示,横轴为设置的成本上限 ,纵轴为预计算推荐结果的收益 。
Benefit-Base、Rule-Based相比于各种贪心算法(Top-Fre、Top-Ben、Top-Over)能够带来的收益上限是更高的,原因是各种贪心算法只是从工作负载的SQL考虑,而没有考虑SQL的合并。各种贪心算法适用的场景也不同,比如在当前工作负载中,Top-Fre表现不好的原因是当前工作负载中的语句重复的很少。
Benefit-Base和Rule-Based能够带来的收益上限近似,但Benefit-Base可以灵活的设置成本上限,并选择在当前成本上限的前提下最大收益的预计算集合,Rule-Based并没有做到这点。
6、结论
本文设计了一种面向时序数据库的预计算推荐系统,包括数据采集、负载分析和预计算推荐三个部分,并设计了两种预计算推荐算法,包括基于规则的预计算推荐算法和基于收益的预计算推荐算法,自动地为用户推荐出相应的预计算集合以最大化数据库的查询效率。通过实验验证,我们的算法能够显著提高查询性能和效率。
总的来说,我们的研究为时序数据库领域中预计算自动化推荐提供了一个有效的解决方案,这对于处理大规模时序数据的应用具有重要意义。未来的工作可以进一步优化算法性能,并将其应用于更广泛的应用场景中,以满足不断增长的时序数据处理需求。
参考文献
[1] Huang Xiangdong, Zheng Liangfan, Qiu Mingming, et al. Time series data aggregation index[J]. Journal of Tsinghua University: Science and Technology, 2016, 56(3): 229−236, 245 (in Chinese) (黄向东,郑亮帆,邱明明,等. 支持时序数据聚合函数的索引[J].清华大学学报:自然科学版,2016,56(3):229−236,245)
[2] Han Y, Li G, Yuan H, et al. AutoView: An Autonomous Materialized View Management System with Encoder-Reducer[J]. IEEE Transactions on Knowledge and Data Engineering, 2022.
[3] Chirkova R, Yang J. Materialized views[J]. Foundations and Trends® in Databases, 2012, 4(4): 295-405.
[4] Rollup And Pre-Aggregates — OpenTSDB 2.4 documentation
[5] InfluxDB Enterprise Documentation (influxdata.com)
[6] PostgreSQL ++ for time series and events | Timescale
[7] TDengine 文档 | TDengine 文档 | 涛思数据 (taosdata.com)